What is Server Load Balancing?
Background
The availability of mission critical applications is without a doubt the IT administrators’ most important priority. Downtime on mission critical application costs organizations in terms of money, lost customers and much more. According to a new report by Ireland-based IT solutions company, ERS IT Solutions, on average IT downtime costs businesses $1.55 million every year.
Availability is not something that you can ignore. You need to design and build your in infrastructure with availability in mind from day one. And server load balancing is the core technology to reliably maximize application availability.
What is server load balancing?
A good question to clarify before we continue.
Server load balancing is the technology to distribute client requests intelligently and dynamically to the mission critical applications running across multiple servers.
The following are a typical rundown of how server load balancing works:
- User accesses the application
- The request received by load balancer sitting in front of physical servers which application is running on.
- The load balancing algorithms decides which physical server user request is forwarded to. Typically the user request will be forwarded to ONLINE and best available physical server. This effectively eliminates the possibility for user to access overloaded physical servers.
- The application receives the user request from load balancer and processes it and sends back a response to load balancer.
- Load balancer forwards response from application to the user
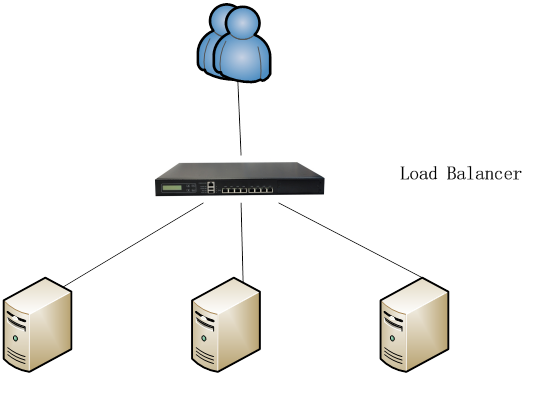
How Server Load Balancing works?
On the surface it’s pretty simple, but as with all technology, the deeper you drill down, the more complex things become.
- The load balancer checks the health status and performance metrics of physical server/applications. When physical server/application is down, the load balancer will take it out of the server pool so it will not server the user request.When physical server/application is up, it will automatically put back to the server pool.Considering the nature of mission critical application there is simply no way that health check on every single application out there can be included in load balancer.
For some regular applications like website, mail system, DNS server etc., the built-in health checks like layer 7 HTTP response check, layer 4 ICMP, or telnet can do its job. However, for some applications like freeradius server, port 1812 probing might not be working. You might run into the situation where port 1812 is up but freeradius daemon is gone.
That is why customization on health status check on applications is critical for load balancer.
- Load balancer utilizes different methods to forward user requests to the physical server/application
Here are various load balancing methods available, and each method uses a particular criterion to distribute user requests across physical server/application.Round robin
The user request is routed to each available physical server/application in a sequential manner.
Ratio round robin
A static weight is preassigned to each server and is used with the round robin method to route the user request.
Least connection
The server with lowest number of current connections is used for the user request.
Ratio least connection
A weight is added to a server depending on its capacity. This weight is used with the least connection method to determine the load allocated to each server.
Predictive
The weight of each server is assigned and most of the user requests are routed to the server with the highest priority. If the server with the highest priority fails, the server that has the second highest priority takes over the services.
Ratio Response Time
The server weight is determined by its response time.
Source IP hash
An IP hash is used to determine the server which handles the user request. - Layer 4 and Layer 7 load balancing
Layer 4 load balancing makes user requests distributed at the transport layer. The layer 4 load balancing only forward packets without inspecting the packet contents. Compared to layer 7 load balancing, layer 4 load balancing brings better performance and throughput.Layer 7 load balancing, allows the load balancer to use application level date to determine how to route each user request entering the applications. Some use cases:
– Direct customer device type to specific web server. For instance, if the request came from a cell phone, the request is directed to a server that is capable of serving content that the user can view on cell phone. A request from a computer is directed to a different server that is capable of serving content designed for a computer screen.
– Direct request based on language. The HTTP Header Accept-Language will be inspected to determine the language used by customer’s browser.
– Route the traffic to specific backend servers based on URL pattern matching, for instance, any URL containing images will be routed to static content server while other URL redirected to dynamic content backend servers.
– Route the traffic based on customer’s source IP to different backend servers.
Server load balancing offers the efficient way to scale out the application infrastructure, optimize service delivery and increase application uptime and service scalability for servers.